串及串的操作
相关定义
串,即字符串,是由零个或多个字符组成的有限数列。一般记为$S=’a_1a_2\dots a_n’$ $n\ge0$
子串:串中任意个连续的字符组成的子序列。
主串:包含子串的串。
字符在主串中的位置:字符在串中的序号。
子串在主串中的位置:子串的第一个字符在主串中的位置。
位序从1开始,而不是从0开始。
注意区分空串与空格串。
串是一种特殊的线性表,数据元素之间呈线性关系。串的数据对象限定为字符集(如中文字符、英文字符、数字字符、标点字符等)。串的基本操作,如增删改查通常以子串为操作对象。
串的存储结构
串的顺序存储
1 |
|
串的链式存储
1 | /* |
如何理解结构体自己包含自己?
当使用了
struct StringNode之后,编译器就认为已经声明了StringNode这种类型,但是还没有完全声明完毕,因为结构体内部有什么编译器还不知道,因此这时尝试声明StringNode node是不通过的,但是可以声明一个指针:StringNode *node,这样编译通过,因为指针大小是确定的。而这也刚好满足我们的需求——结构体内部包含一个指向下个节点的指针。以上为阅读知乎大佬的回答后的总结。
再补充另一位大佬的回答:
“一个结构体里包含一个指针,这个指针指向的数据类型是这个结构体的数据类型。这个指针指向的数据类型是这种结构,但不一定是自己所在的这个结构。”
“区分数据类型和数据实例,数据类型是一种数据,实例是定义出的具体的一个对象。比如定义一个
int i;,int是数据类型,i是数据实例。
所以,当你用这个结构声明出一个变量之后,里面包含的那个指针只是个指针而已,在被你赋值之前它并没有指向自己,之后你给它赋谁的值,它就指向谁。““另一个疑惑可能是想这个结构还没定义完怎么就能在内部用,可以这样理解,对编译器来说,反正所有的指针占用的空间都是一样的,你只要告诉编译器这是个指针就行了。那么既然本质上没区别,那么编译器也就没必要深究这个指针类型到底是咋回事,反正糊弄过去就完了。事实上也有很多代码干脆就把这个指针定义成
void*的,就是为了糊弄一些爱较真的编译器。”
串的基本操作——以堆分配存储表示为例
上面使用的是结构体。这里使用C++的面向对象方法,定义一个我们自己的string类,不妨命名为string_s
1 |
|
如上,为这个类定义了私有变量ch_和length_。前者为一个char类型指针,指向存储的字符串,length_则标识该字符串的当前允许的最长长度。
同时定义了构造函数string_s和析构函数~string_s。
此外,还重载了运算符[],以实现直接取下标对应的字符操作。
要实现的操作有赋值操作、复制操作、判空操作、求串长、清空操作、销毁串、串联接、求子串、定位操作、比较操作,重点实现赋值操作、判空操作、求串长、清空操作、定位操作,这些函数都位于string_s对象中的public块中,最后将会给出完整的string_s.h代码。
赋值操作
将传入的字符数组进行深拷贝,要注意的是,串中第1个元素(下标为0)是空着的,从第2个元素进行赋值。此外,需要为结尾添加上\0。
1 | void str_assign(const char* chars) const |
求串长
从1开始计数,直至出现\0。
1 | // get string length |
判空操作
借助求串长实现。
1 | bool str_empty() const |
清空操作
直接设置第2个元素(下标为1)为\0即可。
1 | // clear string; its length won't be changed |
销毁串
由析构函数实现。
打印字符串方法
使用一个循环依次打印字符,直至\0为止。要注意下标从1开始。
1 | // print string |
定位操作——串的模式匹配
若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置,否则返回0。
简单的模式匹配算法
即将主串的与模式串长度相同的真子集依次与模式串进行对比。
举例如下:
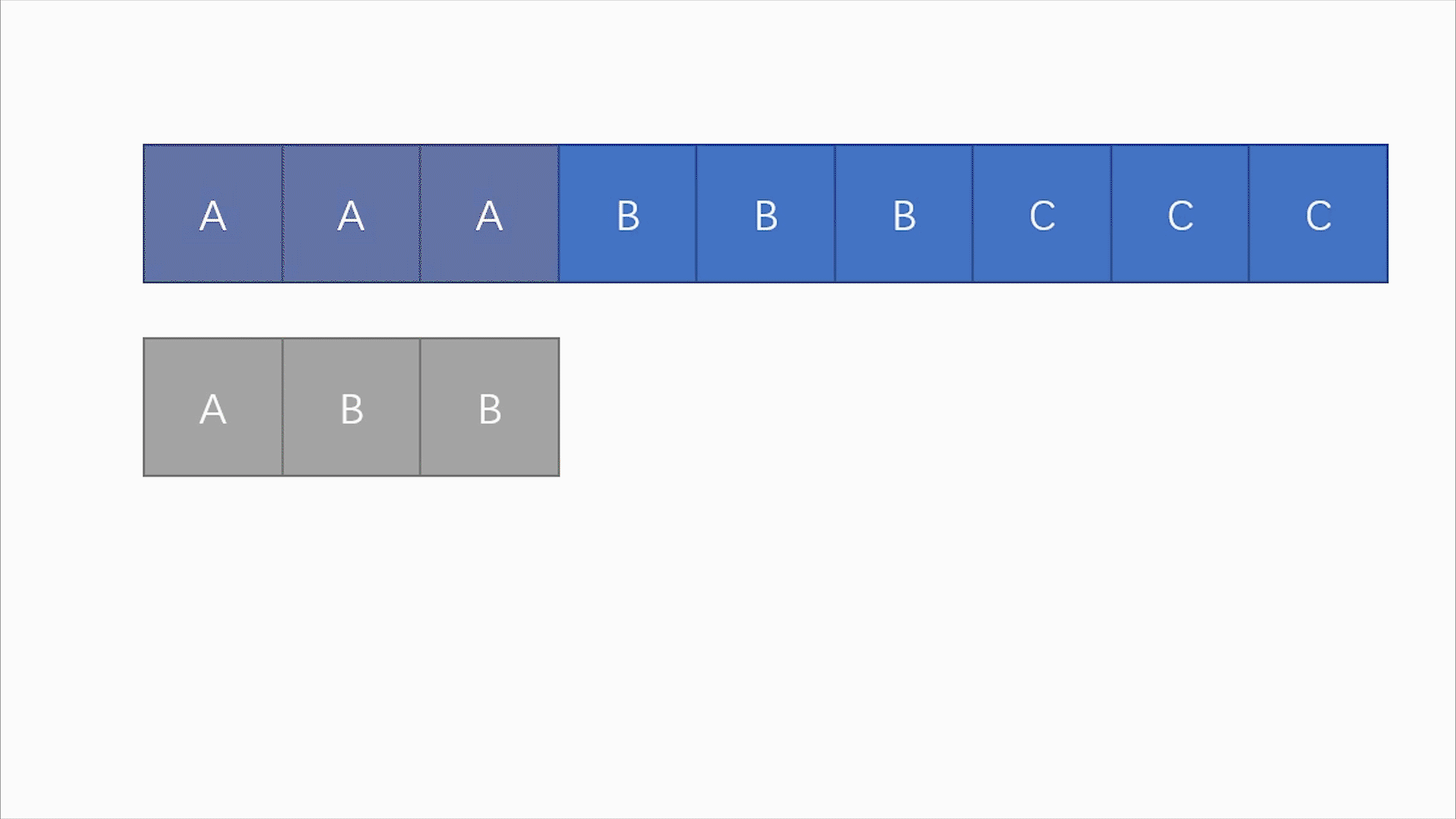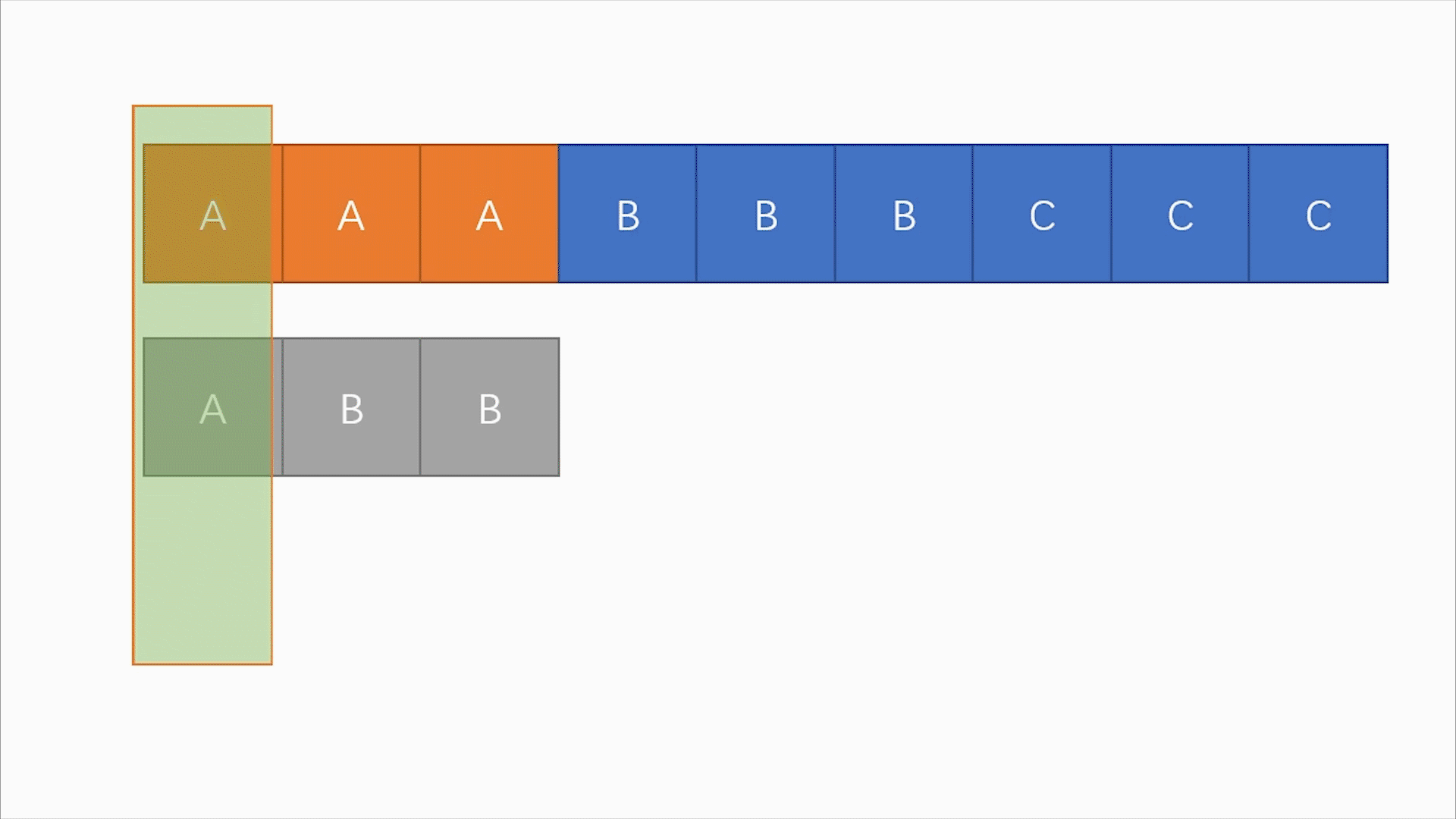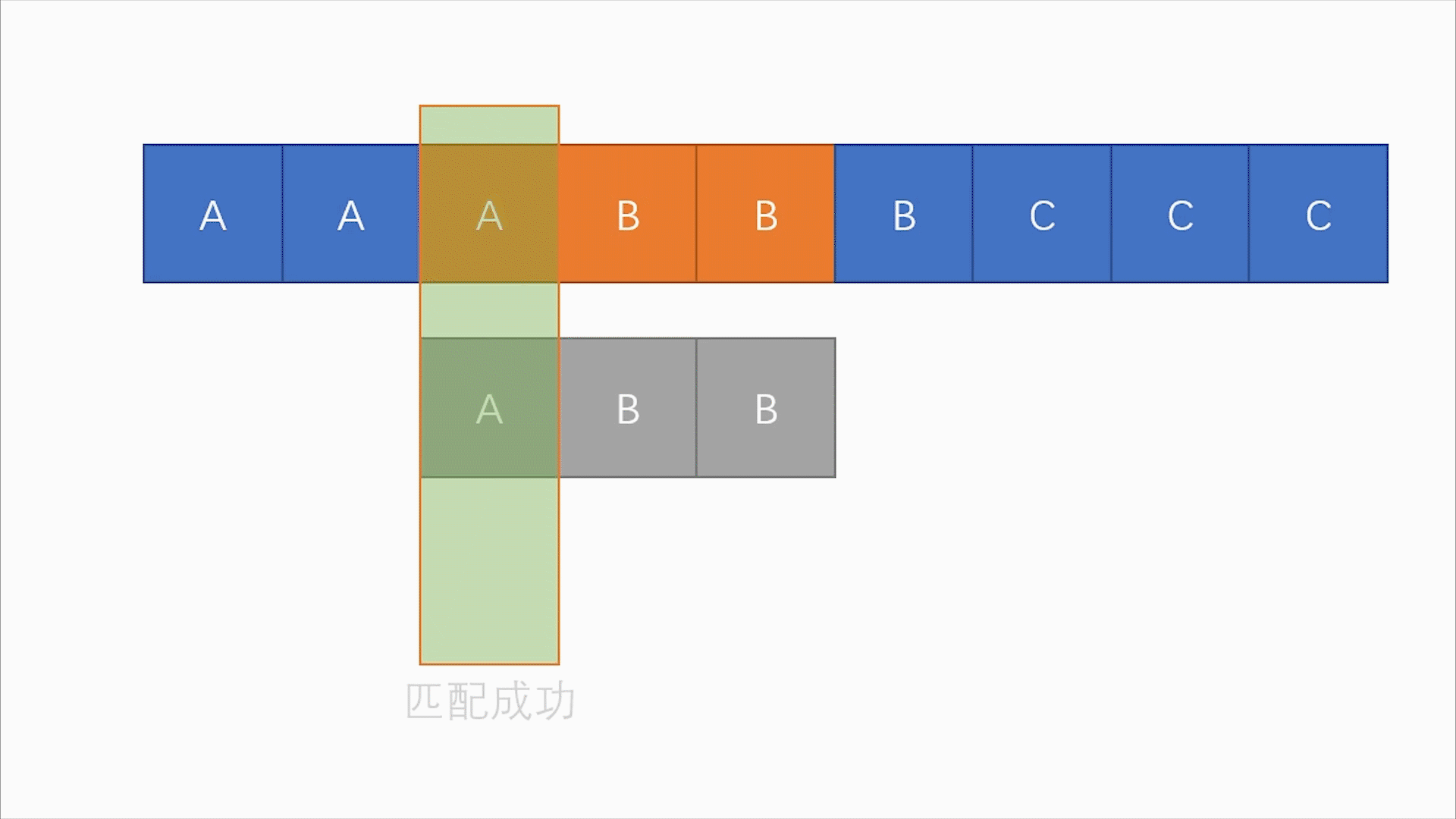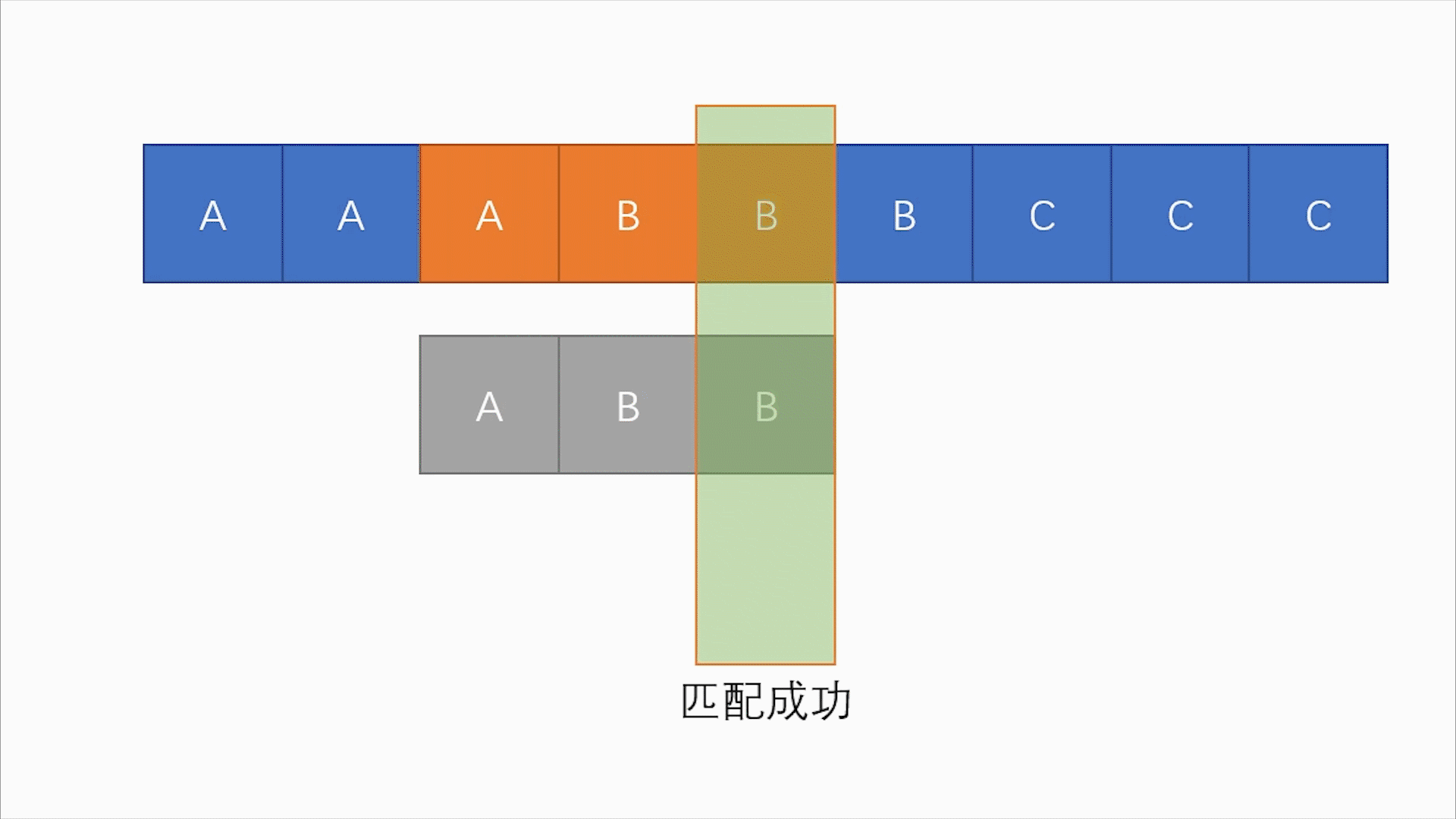
主串
S为:aaabbbccc模式串
T为:abb比对
S[1:3](S的第1个到第3个字符,即aaa)与T(abb)
比对
S[1]与T[1],比对通过。比对
S[2]与T[2],比对失败。
S[3]与T[3]不需要再比较了比对
S[2:4](aab)与T(abb)
比对
S[2]与T[1],比对通过。比对
S[3]与T[2],比对失败。
S[3]与T[3]不需要再比较了比对
S[3:5](abb)与T(abb)
- 比对
S[3]与T[1],比对通过。- 比对
S[4]与T[2],比对通过。- 比对
S[5]与T[3],比对通过。成功找到匹配值。

代码实现如下:
1 | int simple_pattern_match(const string_s& pattern) const |
改进的模式匹配算法——KMP算法
代码先咕咕咕,后面补上
KMP算法的进一步优化
先咕咕咕,后面补上
个人理解:
对变量使用&,得到的是这个变量的地址,这里的变量也可以是指针变量。因此对指针变量取址,得到的是指针变量的地址(一般写成十六进制)。
对一个指针变量使用*,得到的是这个指针变量指向的变量,如果指针变量指向的也是指针变量,那就是得到这个指针变量指向的指针变量。
一个例子:
1 | const char *a = "A"; |
如上,a是一个静态char型指针变量(其类型为const char *),*a是指针变量指向的字符A(其类型为char),&a是指向字符A的指针变量的地址,用十六进制表示为0x61fe18。
综上,我的理解是指针变量与地址仍然有区别,前者相当于类,后者相当于其实例。前者是一种类型,后者是其表现形式。如果将指针变量和地址直接等同,那解释对指针变量取址是什么意思恐怕就更加麻烦了,如何为一个地址取地址呢?

